





![Top 500+ WhatsApp Bio Ideas for Boys & Girls [Funny, Attitude, Cool, Short]](https://azaditimes.com/wp-content/uploads/2025/05/freepik__the-style-is-candid-image-photography-with-natural__63005-768x768.jpeg)






Everyone has access to AI image generators now. Midjourney, DALL-E, Stable Diffusion—the names are familiar. But here’s what nobody talks about: control.
You want a specific style. A consistent character. A particular aesthetic that matches your brand or vision. So you craft elaborate prompts, add negative prompts, tweak parameters, and still get results that feel… generic. Like they came from the same machine everyone else is using. Because they did.
The real power in AI creation isn’t generation. It’s training. Teaching the machine your specific visual language so that even simple prompts produce results that feel uniquely yours. But model training has historically required Python scripts, GPU rentals, and enough technical knowledge to make most creators quit before they start.
That changed when I found ModelScope Vision.
What Is ModelScope Vision?
ModelScope is Alibaba’s open-source AI model ecosystem—think of it as GitHub specifically for artificial intelligence models. Within this ecosystem sits ModelScope Vision, a browser-based platform that handles image generation, video generation, and—crucially—custom LoRA model training entirely through a web interface.
No code. No installations. No credit card required.
The platform operates on a credit system: 200 free credits upon signup, plus 100 additional credits daily. For context, a standard image generation costs a fraction of a credit, and model training is completely free. Watermark-free exports don’t trigger paywalls. Advanced generation with negative prompts and multiple model selections runs without subscription nagging.
In an industry where “free” usually means “free until you need quality,” this feels almost suspicious.
The Feature That Changes Everything: LoRA Training
 LoRA (Low-Rank Adaptation) training allows creators to teach AI models specific visual styles using just 10-15 reference images.
LoRA (Low-Rank Adaptation) training allows creators to teach AI models specific visual styles using just 10-15 reference images.Why Custom Models Matter
Here’s the scenario. You run a faceless YouTube channel. Your content requires a consistent 2D cartoon aesthetic. Without custom training, every prompt becomes a negotiation: “2D cartoon style, flat colors, thick outlines, anime-inspired but western…” You write paragraphs. The AI interprets differently each time. Consistency becomes a battle.
With LoRA training, you upload 10 to 15 images representing your desired style. You name the model. You set a trigger word. The platform trains for free. And suddenly, typing “a man walking in a river” produces exactly your aesthetic—no style descriptors needed.
The workflow transforms from prompt engineering to creative direction.
How the Training Works
The process is deliberately simple:
- Navigate to the training section
- Select a base reference model (the foundation the AI builds upon)
- Name your LoRA model and set a trigger word
- Upload 10-15 representative images
- Click “Start Free Training”
Training completes in minutes to hours depending on queue length. Once finished, the model appears in your personal library, accessible during any generation task by filtering for “My Models.”
I trained a 2D illustration model using a curated set of cartoon references. The result? Typing “detective examining clues” produced an image that looked like it belonged in the same universe as my training set—without mentioning art style, medium, or visual references once.
Image Generation: Beyond the Basics
 The landscape of AI image generation has exploded, but few platforms offer the depth of control available through ModelScope Vision.
The landscape of AI image generation has exploded, but few platforms offer the depth of control available through ModelScope Vision.Instant vs. Advanced Generation
ModelScope Vision offers two generation modes:
Instant Generation handles quick outputs with basic parameters—prompt, size, quantity. It’s fast, functional, and produces quality suitable for most social media content.
Advanced Generation is where professionals live. This mode adds:
- Negative prompts (specify what you don’t want)
- Multiple model selection (combine base models with your custom LoRA)
- Reference image input (use your face or existing artwork as structural guidance)
- Enhanced parameter control for fine-tuning output characteristics
I tested advanced generation using a complex cinematic prompt from ChatGPT—something involving dramatic lighting, specific camera angles, and atmospheric elements. The output matched the prompt with surprising fidelity, maintaining coherent physics and proper light sourcing that often breaks in lesser tools.
The Watermark Surprise
Most “free” AI platforms watermark outputs and demand payment for clean versions. ModelScope Vision offers watermark-free generation as a standard option. Clicking it doesn’t redirect to a pricing page. It simply generates without the logo. This alone saves creators hours of post-processing or subscription fees.
Face Swapping and Character Consistency
Upload a reference image of yourself, select a model, and generate. The platform maintains facial structure while applying the requested scenario. I generated a “detective” version of myself that preserved recognizable features while adopting the requested mood and setting. For creators building personal brands or consistent characters, this eliminates the randomness that plagues standard generation.
Video Generation: The Final Frontier
 Text-to-video technology represents the next evolution in AI content creation, with open-source platforms leading accessibility.
Text-to-video technology represents the next evolution in AI content creation, with open-source platforms leading accessibility.ModelScope Vision doesn’t stop at images. The platform offers three distinct video generation approaches:
Image-to-Video
Upload a static image and animate it using text prompts. I tested this with a generated action scene, prompting “man running and shooting with a gun.” The resulting video maintained character consistency while adding fluid motion—no morphing, no sudden identity shifts, no nightmare fuel.
First Frame + Last Frame
This is where it gets cinematic. Upload two images representing your opening and closing shots. The AI generates the transition between them. I created a sequence showing a character in two different poses, and the platform produced a smooth, logical movement connecting the states.
The quality impressed me. Motion felt intentional rather than algorithmic. Physics remained coherent. For creators building narrative sequences or music visualizers, this feature alone justifies exploration.
Text-to-Video
Direct generation from text prompts without image inputs. While currently less controllable than image-based methods, it offers genuine utility for abstract concepts or when source imagery isn’t available.
All video outputs are watermark-free. Length and resolution parameters are adjustable. And the entire pipeline runs within the same credit system—no separate “video credits” or premium tier requirements.
The Technical Backbone: Why This Actually Works
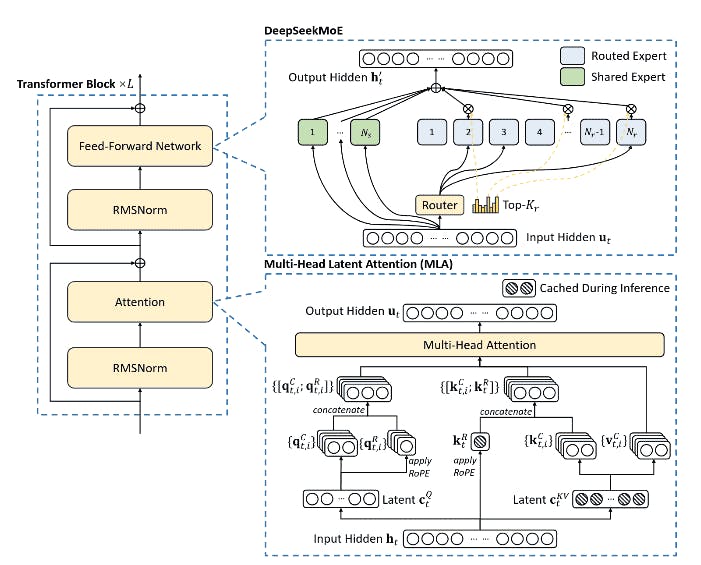 Advanced models like DeepSeek and Qwen power ModelScope’s ecosystem, offering capabilities that rival proprietary alternatives.
Advanced models like DeepSeek and Qwen power ModelScope’s ecosystem, offering capabilities that rival proprietary alternatives.ModelScope isn’t a scrappy startup burning venture capital. It’s backed by Alibaba’s DAMO Academy, one of the world’s largest AI research organizations. The platform integrates models that others charge premium rates for:
- DeepSeek (advanced language and multimodal models)
- Qwen (Alibaba’s flagship LLM series)
- Stable Diffusion variants optimized for specific use cases
- Custom community models uploaded by researchers and creators
The free API tier offers 2,000 daily calls for advanced models. For developers building applications or automating workflows, this replaces paid API subscriptions that typically cost hundreds monthly.
Mobile-First Design
Everything runs in browser. No app installation. No desktop GPU requirements. I tested the entire workflow—model training, image generation, video creation—on a mid-range Android phone. Performance remained smooth, proving that sophisticated AI work no longer requires hardware investments.
The Credit Economy: How Far Do Free Credits Actually Go?
Let’s break down the math because “free” means different things on different platforms:
| Activity | Credit Cost | Free Tier Capacity |
|---|---|---|
| Standard image generation | ~0.5-2 credits | 100-400 images daily |
| Advanced generation | ~2-5 credits | 40-100 images daily |
| Model training | Free | Unlimited models |
| Video generation (8 sec) | ~10-20 credits | 10-20 videos daily |
| API calls (advanced models) | 2,000/day | Separate quota |
With 200 signup credits plus 100 daily refills, casual creators can generate substantial content without spending money. Heavy users can link Alibaba Cloud accounts for an additional 50 daily credits.
The invitation system adds another layer: using a referral code during signup grants double initial credits (400 instead of 200). Both parties benefit, creating genuine incentive for community growth rather than extraction.
Real-World Use Cases: Who Actually Benefits?
Faceless YouTube Creators
Train a consistent character model. Generate unlimited variations. Animate for B-roll. The entire pipeline—from concept to final video—happens within one platform without subscription stacking.
Indie Game Developers
Rapid prototype character designs. Generate texture variations. Create promotional artwork in a unified style. The LoRA training ensures visual consistency across hundreds of assets.
Social Media Managers
Produce daily content without quality degradation. Train brand-specific aesthetics. Generate video content for Reels, TikTok, and Shorts from static campaign imagery.
Writers and Concept Artists
Visualize scenes without artistic skill. Maintain character appearance across multiple illustrations. Explore mood and atmosphere through rapid iteration.
Developers and Startups
Build AI-powered applications using the free API. Prototype features without infrastructure costs. Scale only when revenue justifies investment.
The Limitations Nobody Talks About
Transparency requires acknowledging boundaries:
Queue times vary. Free users share processing resources with millions of others. During peak hours, generation might take minutes rather than seconds. Patience becomes part of the workflow.
Model training quality depends on input curation. Uploading random images produces random results. The 10-15 training images need curation, consistency, and clear representation of your desired output.
Video length caps exist. Current generation limits hover around 8-12 seconds per clip. Longer narratives require stitching multiple generations, which demands additional editing.
English interface support is functional but occasionally awkward. ModelScope originates from China, and while the web interface translates reasonably well, some advanced documentation remains Chinese-language.
Account verification requires email access. The verification email sometimes lands in spam folders. Users need to check thoroughly before requesting resends.
How to Get Started: A Practical Walkthrough
Step 1: Account Creation
Visit ModelScope Vision through the official portal. Create an account using email registration. During signup, enter an invitation code if available—this doubles your initial credits from 200 to 400.
Critical note: Check your spam folder for the verification email. It doesn’t always arrive in primary inboxes.
Step 2: Explore the Interface
Familiarize yourself with three main sections:
- Image Generation (instant and advanced modes)
- Video Generation (image-to-video, text-to-video, first/last frame)
- Model Training (LoRA creation interface)
Step 3: Train Your First Model
- Collect 10-15 images representing your desired style
- Navigate to training, select a base model
- Name your model and set a trigger word (e.g., “MYSTYLE”)
- Upload images and start training
- Wait for completion notification
Step 4: Generate Content
Use your trained model in advanced generation by selecting it from “My Models.” Test with simple prompts first—let the LoRA handle the stylistic heavy lifting.
Step 5: Scale Strategically
Link an Alibaba Cloud account for bonus credits. Use the API for automated workflows. Build a content calendar around your daily credit refresh.
The Bigger Picture: Open Source vs. Proprietary AI
 Open-source models like DeepSeek are increasingly competitive with proprietary alternatives, challenging the paid subscription model.
Open-source models like DeepSeek are increasingly competitive with proprietary alternatives, challenging the paid subscription model.ModelScope Vision represents something larger than a single tool. It’s evidence that open-source AI ecosystems can match—and sometimes exceed—proprietary alternatives without paywalling creativity.
While Western platforms race to monetize every generation, Chinese tech companies have pursued a different strategy: ecosystem building. By making advanced tools freely accessible, they cultivate user bases, gather training data, and establish platform loyalty. The long game isn’t subscription revenue; it’s becoming infrastructure.
For creators, this creates a window. These tools won’t remain unlimited forever. Platforms eventually monetize. But right now, the combination of genuine functionality, generous free tiers, and no-code accessibility makes ModelScope Vision arguably the most creator-friendly AI platform available.
Final Assessment: Should You Use It?
If you’re a casual user who generates occasional AI art for entertainment, ModelScope Vision is overkill. Stick with ChatGPT’s DALL-E integration or Bing Image Creator.
But if you’re a serious creator building consistent content, this platform solves problems that cost hundreds monthly elsewhere. Custom model training alone justifies exploration. Add watermark-free video generation, daily credit refreshes, and API access, and the value proposition becomes undeniable.
The learning curve is gentle. The output quality is professional. The price is genuinely zero.
In an industry where “free” usually means “free trial,” ModelScope Vision offers something radical: free capability. And that might be the most disruptive thing in AI right now.
Have you trained custom AI models before? What challenges did you face? Share your experience in the comments below.

{kind=link}